
Ce n’est un secret pour personne : un code de qualité est souvent synonyme d’un code bien testable et bien testé. Alors à vous les pratiquants de tests chevronnés, je veux poser les questions suivantes : ne vous est-il jamais arrivé de voir des pratiques de code barbares au nom de la toute puissante couverture de code ? Ne vous est-il jamais arrivé de dégrader le code de production pour faciliter le code de tests ? Ou encore de maintenir des tests qui ne vous apportent aucune garantie ?
En me basant exclusivement sur mon expérience de ces 2 dernières années, je vais partager, à travers différents articles sur les tests, certaines dérives de mise en application des tests automatisés que j’ai pu rencontrer, ainsi que les conclusions que j’ai pu en tirer.
Ici nous allons nous intéresser à une dérive que j’ai pu constater sur un certain nombre de projets : le détournement du scope de méthodes “public” au service des tests. Ceci se traduit par l’existence de méthodes publiques uniquement consommées par leurs classes. Pour comprendre comment on peut en arriver à dégrader le code de production* de cette façon, il faut d’abord comprendre pourquoi il est important de focaliser nos tests sur les méthodes publiques.
Pourquoi tester uniquement les méthodes publiques ?
Projetons nous dans une dimension avec les 2 assertions suivantes :
- Tu es invité chez moi pour l’apéro
- Et j’ai de sacrées bouteilles de rhum et de whisky
Cela t’intéresse-t-il vraiment de savoir que mes bouteilles sont belles ? A mon sens non et ça ne devrait pas. En revanche ce qui devrait t’intéresser, c’est de savoir si ce que je vais te proposer à boire donnera mal aux cheveux le lendemain ou pas.
Mon point ici, c’est que dans l’implémentation d’une classe (dans notre cas Bar), la seule chose qui intéresse les consommateurs de cette classe est ce qu’elle expose et non ses contenus et mécanismes internes. Ainsi l’idée avec mes tests unitaires va être de m’assurer que mon bar se comporte comme attendu vis-à-vis de ses consommateurs aujourd’hui (spécification), et qu’il en sera toujours ainsi si plus tard je déménage mon bar ou que j’y ajoute des bouteilles (non-régression).
En l’occurrence si ma classe a deux méthodes getAllSofts() et getAllAlcools() , qu’en penses-tu ?

Justement pas si vite ! Elles sont privées donc ne crois pas pouvoir en faire ce que tu veux. Je t’annonce maintenant que toi, en tant que consommateur, tu n’auras accès qu’à une méthode publique proposeDrink(). Et moi, en tant qu’hôte de la soirée, je vais te faire une confession : pour te proposer une boisson, je vais m’appuyer sur getAllSofts() et getAllAlcools() pour déterminer ce que j’ai en stock, mais pour te montrer qui est le patron, je ne vais te proposer que mes 2 bouteilles avec le plus grand taux d’alcool.

Sans cette confession, comment pourrais-tu t’assurer du lien qu’il existe entre les méthodes proposeDrink() et l’état de mon stock ? Eh bien tu ne le peux pas et ce ne sont pas tes affaires ! Alors concentrons nos tests sur notre méthode publique proposeDrink() ;).
Focaliser nos tests sur des méthodes privées, qui par nature ne sont pas exposées aux objets extérieurs, ne peut en aucun cas nous prémunir contre d’éventuelles régressions de l’application en cas d’évolutions de ces dernières.
Les fausses méthodes publiques : un nouvel espoir
Nous venons ensemble d’établir pourquoi il ne faut tester que les méthodes publiques.
Si cette règle était absolue, on pourrait accorder une confiance aveugle à nos testeurs néophytes et cet article n’aurait pas lieu d’être… Mais comme le dit si bien Donald Sutherland dans Braquage à l’italienne “I trust everyone, It’s the devil inside them I don’t trust.”.
Ici le diable en question pousse les gens à créer ce que j’appelle de fausses méthodes publiques, à savoir des méthodes publiques uniquement consommées par leurs classes.
Ayant croisé le fer avec ces méthodes 2 fois ces derniers mois, je te propose dans la continuité de cet article qu’on analyse ce problème, verre à la main !
Supposons que mon bar jusque-là exposait une méthode proposeDrink(origin:Country) bien testée et que maintenant nous ayons besoin d’enrichir cette fonctionnalité avec la possibilité de choisir le type d’alcool.
Dans une situation similaire, un ancien collègue m’a proposé la solution suivante :
- Conserver la méthode proposeDrink telle quelle (algo + scope publique), ceci afin d’éviter de modifier tous ses tests
- Créer une méthode proposeDrinkBis dans la même classe qui appellerait proposeDrink et sur laquelle on ajouterait juste les tests sur le type d’alcool
En schéma voici ce que cela donne :
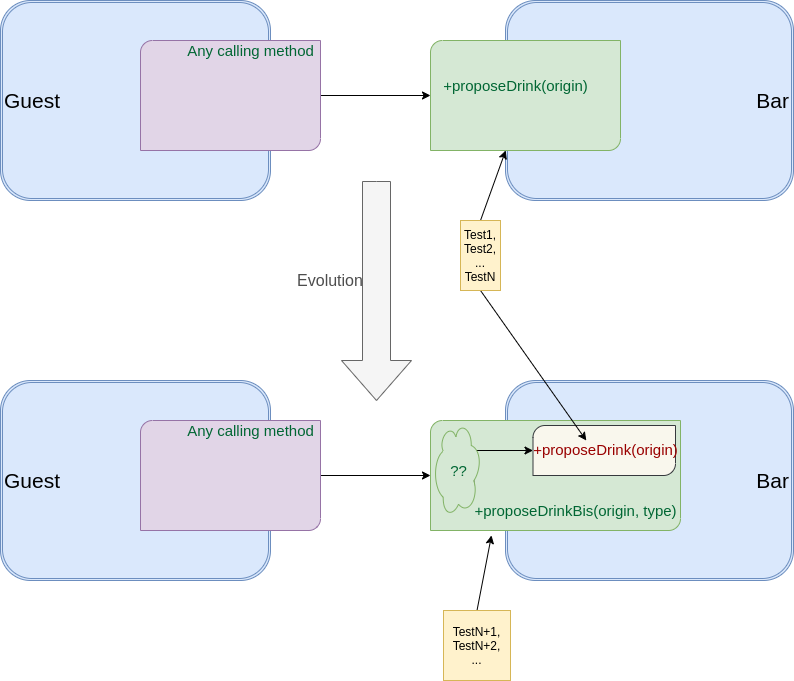
De cette manière proposeDrink devient une fausse méthode publique, gardée publique pour limiter les modifications de code (production + tests) et boucler notre US au pas de course ! Voyons maintenant le contre coup de cette solution rapide …

La trahison des fausses méthodes publiques
Tout d’abord nous avons conservé le scope public sur proposeDrink afin de conserver ses tests. Or dans les faits, proposeDrink n’a plus vocation à être appelée par nos guests : nous retombons sur le problème décrit précédemment concernant les tests de méthodes privées. Ainsi les consommateurs habitués jusqu’ici à choisir une boisson par son origine grâce à proposeDrink dont le fonctionnement était assuré, ne sont plus assurés que cette fonctionnalité n’a pas été altérée s’ils passent par proposeDrinkBis (non-régression non garantie).
Par ailleurs conserver un scope publique sur proposeDrink peut avoir la communication suivante pour d’autres développeurs :

Par conséquent, la probabilité que ces derniers l’utilisent à tort dans le cadre d’implémentations d’autres services s’en trouve accrue (et je ne parle pas du cas où l’on aurait juste surchargé proposeDrink). La fausse méthode publique introduit donc dans notre classe un défaut d’affordance.
Jusqu’à maintenant l’alcool nous a posé bien des problèmes, calmons-nous donc sur la bouteille et trouvons des solutions !
La solution ?
Dans le fond, il suffit d’accepter qu’un logiciel évolue au rythme des besoins métiers, et que par conséquent son code doit changer avec lui.
Le fait est que le développeur se trouve aujourd’hui confronté à 2 besoins qui s’opposent lors de la modification de son produit :
- Assurer une couverture de code par des tests, parfois nombreux, pour garantir la qualité du produit
- Pouvoir ajouter ou enrichir des fonctionnalités existantes rapidement
La couverture de code par les tests a tendance à introduire une inertie du code, de par l’impact que peut avoir la modification du code de production, sur tout le code de test qui le couvre. Il s’agit donc de garder des méthodes publiques limitées dans leur taille et leur complexité, ce qui est directement en corrélation avec leur facilité à évoluer (moins de tests, des tests plus simples, …).
Pour ce faire, je propose de suivre le merciless refactoring tiré de l’extreme programming, l’idée étant de procéder à des petits remaniements de la base de code (code production + test) tout au long des évolutions du projet.
Effectuer des remaniements suppose de déceler les situations où ils apportent de la valeur. Il faudrait un bouquin entier pour expliquer les indicateurs de situations propices au refactoring (commencer par lire le Clean code est un bon début), donc je ne me lancerai pas dedans.
Parmi les questions à se poser en permanence, j’aimerais tout de même mettre l’accent sur ces dernières :
- Cette méthode publique ne fait-elle pas trop de choses ? Ici nous avons plusieurs indicateurs qui peuvent nous aider à le déterminer, tels que la taille de la méthode, des tests unitaires à rallonge, etc….
- Ma classe respecte-t-elle toujours le Single Responsibility Principle (SRP) avec les modifications que j’y ai apportées ? Là aussi un bon nombre d’indices permettent de le révéler, parmi lesquels le nombre de dépendances de la classe, le nombre de méthodes publiques (en excluant les surcharges de méthodes), etc…
Le mot du chef

Nous avons vu ici qu’en ciblant mal nos tests ou qu’en ne nous disciplinant pas avec les petits remaniements du quotidien, non seulement nous perdons tous les avantages des tests, mais en plus qu’il en résulte une inertie de la base de code, en opposition directe à l’évolution du business qu’elle supporte.
Par expérience, ce travail de tous les jours pour le maintien de l’accessibilité et de l’évolutivité d’une application est ESSENTIEL, car tout nouvel ajout de code sur l’existant a mécaniquement tendance à le sortir du droit chemin (il ne suffit que de l’ajout d’une toute petite méthode pour ruiner un SRP, rends-toi compte !). Sans cette discipline, la normalisation de la déviance, notion décrite par Diane Vaughan, a de fortes chances de s’installer sur le projet et d’y rester jusqu’à sa refonte complète !
Pour aider à systématiser le maintien de la qualité du code dans l’application, il existe notamment le TDD et sa phase de remaniement systématique que nous introduit ici Silvio. Cette pratique n’est cependant pas simple à s’approprier et pour cette raison je vous montrerai, dans un prochain article, 2 erreurs d’interprétation courantes des règles et promesses du TDD à éviter.
Cet article finit ici, mais pour les aficionados du code, j’ai ajouté un exemple simple sur les méthodes faussement publiques.
Cas d’étude simple
Ici je vais te montrer avec un exemple assez simple, le cas que j’ai rencontré avec d’abord la solution qu’on m’a proposée et ensuite celle que je te propose.
public class UserFactory {
private UserRepository userRepository;
public UserFactory(UserRepository userRepository) {
this.userRepository = userRepository;
}
public User createUser(UserInfo userInfo) {
if (isEmailInvalid(userInfo.getEmail())) {
throw new InvalidUserEmailException();
}
return userRepository.save(mapToUser(userInfo));
}
private boolean isEmailInvalid(String userInfo) {
// Fake method for example only
return false;
}
private User mapToUser(UserInfo userInfo) {
// Fake method for example only
return null;
}
}Pour limiter le code, je vous demande d’imaginer que la méthode createUser est correctement testée.
Puis dans un second temps nous avons besoin d’ajouter une nouvelle règle de gestion à notre création d’utilisateur, à savoir qu’on ne puisse pas avoir deux utilisateurs avec la même adresse email dans notre système.
Si on se replace dans le cas que j’ai rencontré, la solution qu’on m’a proposée implique de renommer createUser en createValidUser (l’IDE permet ce remaniement sans casser les tests) puis d’ajouter une méthode createUser qui portera notre nouvelle règle et qui sera testée indépendamment (notion de Spy de Junit) :
public class UserFactory {
private UserRepository userRepository;
public UserFactory(UserRepository userRepository) {
this.userRepository = userRepository;
}
public User createUser(UserInfo userInfo) {
String email = userInfo.getEmail();
Optional<User> userFound = userRepository.findByEmail(email);
if (userFound.isPresent()) {
throw new UserEmailAlreadyUsedException();
}
return createValidUser(userInfo);
}
public User createValidUser(UserInfo userInfo) {
if (isEmailInvalid(userInfo.getEmail())) {
throw new InvalidUserEmailException();
}
return userRepository.save(mapToUser(userInfo));
}
private boolean isEmailInvalid(String userInfo) {
// for example only
return false;
}
private User mapToUser(UserInfo userInfo) {
// for example only
return null;
}
}Ainsi un développeur qui souhaite développer un nouveau cas d’utilisation impliquant de créer un utilisateur peut, sans aucune barrière, faire appel à la méthode createValidUser, et ainsi compromettre la cohérence des données de notre système sans casser aucun test.
Maintenant, voici une solution, qui à mon sens, est à privilégier :
public class UserFactory {
private UserRepository userRepository;
public UserFactory(UserRepository userRepository) {
this.userRepository = userRepository;
}
public User createUser(UserInfo userInfo) {
String email = userInfo.getEmail();
Optional<User> userFound = userRepository.findByEmail(email);
if (userFound.isPresent()) {
throw new UserEmailAlreadyUsedException();
}
if (isEmailInvalid(email)) {
throw new InvalidUserEmailException();
}
return userRepository.save(mapToUser(userInfo));
}
private boolean isEmailInvalid(String userInfo) {
// for example only
return false;
}
private User mapToUser(UserInfo userInfo) {
// for example only
return null;
}
}Ici pas grand chose à dire si ce n’est que nous avons fait évoluer la méthode publique ainsi que ses tests. La non-régression des TUs est toujours assurée et les règles métiers protégées ! Non avons dû modifier le comportement des tests existant en définissant un comportement pour userRepository.findByEmail, mais rien de très chronophage puisque la modification s’appliquait de la même façon à tous nos anciens tests !

Pour ceux qui ont relevé le choix étrange de faire des appels au repo alors même que le mail n’est pas valide, vous avez vu juste ! Cela révèle bien que les tests unitaires sur des règles de gestion métier ne garantissent en rien l’efficacité du code…
Cheers !
Marvin Gilly – El Rhum Adorator
Références:
- TDD by example de Kent Beck
- Clean code de Robert C. Martins
- https://en.wikibooks.org/wiki/Professionalism/Diane_Vaughan_and_the_normalization_of_deviance
- https://stackify.com/oop-concept-for-beginners-what-is-encapsulation/
Images:
- The Office
- Allez viens
- Star wars / Death Note / pirate des Caraïbes
- https://imgflip.com/memegenerator/85980921/coloring-kid