Après quelques années à faire passer des entretiens techniques et à accompagner de jeunes développeurs sur la technique, mon constat est sans appel : Git, l’outil de versionning le plus utilisé du marché, n’est toujours pas compris par une bonne partie de ses pratiquants. Alors pour ce début d’année, je laisse le testing et autres pratiques de la mouvance craft de côté pour décrypter et démystifier un peu les mécaniques que cet outil met en œuvre. Mais puisque nous ne pouvons pas tout balayer sur un article, nous allons aujourd’hui voir en détail à quoi correspond un commit !
Pour faire les manipulations de cet article avec moi, pensez à installer git et avoir un outil de ligne de commandes linux (vous pouvez utiliser le gitbash fourni avec l’installation de git sur windows pour les fans de Cortana).
Des objets dans notre base de données locale
Un commit est un snapshot du projet, associé à un timestamp, un auteur, un commit parent et un message. C’est pour cela qu’à chaque fois que vous faites des modifications dans votre projet, vous enregistrez la nouvelle version du projet avec un commit. Attention, Git n’enregistre pas les delta*, il enregistre un nouvel état… C’est juste qu’il le fait de façon super efficace !
Voici l’exemple reprenant 4 commits sur lequel nous allons nous baser pour nos explications :
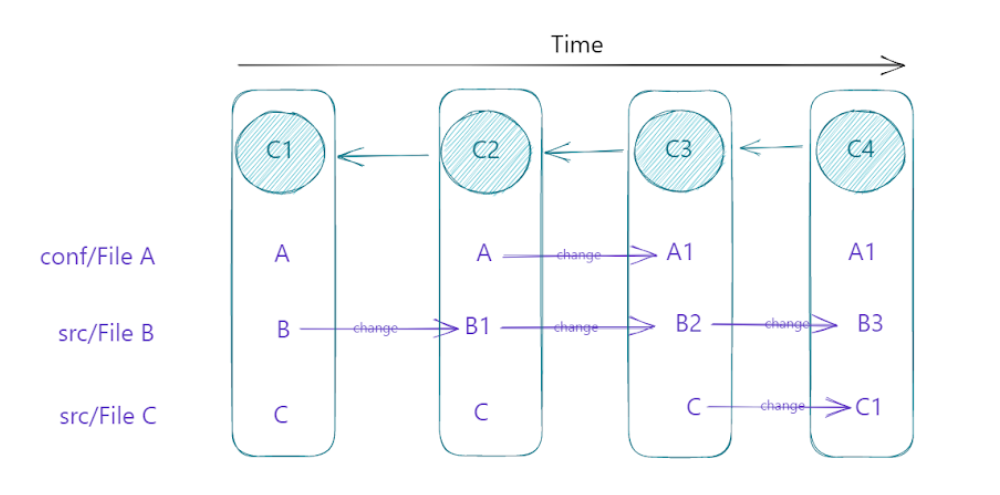
Git a beau ne pas stocker les deltas*, il ne va pas pour autant se lancer dans la duplication des fichiers inchangés d’un commit à l’autre… Alors que se passe-t-il sous le capot ?
Il faut voir Git comme une base de données locale située dans le dossier .git de votre projet et qui contient notamment plusieurs types d’objets. Ici, nous allons nous attarder sur les objets de type commit, tree et blob.
Pour voir concrètement ce qu’il se passe, créons notre projet git avec les commandes suivantes :
$ mkdir gitlearning; cd "$_"
$ git initNous nous retrouvons alors avec le dossier .git qui va contenir toutes les données permettant d’utiliser notre outil de versionning sur le projet gitlearning :
$ ls .git -a
./ ../ HEAD config description hooks/ info/ objects/ refs/Nous allons ici surtout nous pencher sur le dossier objects qui va contenir nos différents types d’objets (commit, tree, blob) associés à des hashs.
Commençons par créer l’arborescence de notre exemple avec 3 fichiers dispatchés dans 2 répertoires :
$ mkdir -p src conf
$ echo -n "first content A" > conf/fileA.txt
$ echo -n "first content B" > src/fileB.txt
$ echo -n "first content C" > src/fileC.txtSi nous regardons les objets créés dans git :
$ find .git/objects/ -type fNotre dossier .git/objects ne contient effectivement aucune donnée. Et c’est logique puisque ces modifications ne sont que dans le working directory.
Mais si nous préparons notre commit en ajoutant cette arborescence à l’index :
$ git add src/ conf/Alors le statut de notre repo local change :
$ git status
On branch master
No commits yet
Changes to be committed:
(use "git rm --cached ..." to unstage)
new file: conf/fileA.txt
new file: src/fileB.txt
new file: src/fileC.txt
Et nous pouvons voir que le dossier objects contient 3 nouveaux fichiers dans 3 répertoires distincts :
$ find .git/objects/ -type f
.git/objects/24/4ecfc79b82adadc926d3409d22bfaa4f1f4938
.git/objects/28/a3d34cf482fab0655efe5d4010e01b0620dfbe
.git/objects/85/83cd25271d252695d2f7606c0740149ea1274c
Si nous concaténons maintenant le nom de dossier et le nom de fichier pour les 3 objets créés, nous obtenons 3 hashs de 40 caractères :
$ find .git/objects/ -type f | cut -c14- | tr -d /
244ecfc79b82adadc926d3409d22bfaa4f1f4938
28a3d34cf482fab0655efe5d4010e01b0620dfbe
8583cd25271d252695d2f7606c0740149ea1274c
Nous pouvons alors interroger git sur la nature de ces objets grâce à ces hashs :
$ git cat-file -t 244ecfc79b82adadc926d3409d22bfaa4f1f4938
blobMais aussi leur contenu :
$ git cat-file -p 244ecfc79b82adadc926d3409d22bfaa4f1f4938
first content AOn peut donc déjà en conclure une chose à cette étape : ajouter des fichiers à l’index implique de créer des nœuds de type blob pour ces fichiers !
Si maintenant nous commitons pour la première fois :
$ git commit -m "first commit"
[master (root-commit) f5e463e] first commit
3 files changed, 3 insertions(+)
create mode 100644 conf/fileA.txt
create mode 100644 src/fileB.txt
create mode 100644 src/fileC.txt
Alors nous pouvons voir que nous avons 4 nouveaux objets créés (dossiers 3a, 8a, 8d, f5) :
$ find .git/objects/ -type f
.git/objects/24/4ecfc79b82adadc926d3409d22bfaa4f1f4938
.git/objects/28/a3d34cf482fab0655efe5d4010e01b0620dfbe
.git/objects/3a/c4d6ce59a6466507d45bb914eb6658b3ff2b0c <<<
.git/objects/85/83cd25271d252695d2f7606c0740149ea1274c
.git/objects/8a/f01647c79778b1fd73badd285beec1d4f802f7 <<<
.git/objects/8d/18ccf1ef116db3089d7614cf8594caef920298 <<<
.git/objects/f5/e463e48ba9dc6b36b072ca3cd03d9c2a0bb70b <<<
Par soucis de lecture, je privilégierai la version abrégée des hash pour les commandes suivantes.
En utilisant encore la commande cat-file pour connaître les types de ces 4 objets, on obtient :
git cat-file -t 3ac4d6c => tree
git cat-file -t 8af0164 => tree
git cat-file -t 8d18ccf => tree
git cat-file -t f5e463e => commit
Alors pourquoi 4 nouveaux objets ?
Commençons par regarder le contenu de notre objet de commit :
$ git cat-file -p f5e463e
tree 8d18ccf1ef116db3089d7614cf8594caef920298
author MarvinElRhumAdorator <marvingilly@gmail.com> 1685611832 +0200
committer MarvinElRhumAdorator <marvingilly@gmail.com> 1685611832 +0200
first commit
Sans surprise, nous avons toutes les informations de commit (auteur, timestamp, message) et un lien vers l’objet 8d18ccf … qui est l’un des nouveaux objets que nous avons de type tree ! Inspectons cet objet :
$ git cat-file -p 8d18ccf
040000 tree 3ac4d6ce59a6466507d45bb914eb6658b3ff2b0c conf
040000 tree 8af01647c79778b1fd73badd285beec1d4f802f7 src
Et ici nous avons un tree qui pointe vers les 2 autres nouveaux objets de type tree que nous avons créés : un tree pour le répertoire conf et un tree pour le répertoire src.
Pour faciliter les explications suivantes, nous parlerons de l’objet tree qui est directement associé à l’objet de commit en tant que tree-root.
Il est possible de faire référence au tree-root du commit courant à l’aide de la notation HEAD^{tree} .
Et en répétant l’opération sur ces 2 répertoires :
$ git cat-file -p 3ac4d6c
100644 blob 244ecfc79b82adadc926d3409d22bfaa4f1f4938 fileA.txt
$ git cat-file -p 8af0164
100644 blob 8583cd25271d252695d2f7606c0740149ea1274c fileB.txt
100644 blob 28a3d34cf482fab0655efe5d4010e01b0620dfbe fileC.txt
Il est clair que ces répertoires pointent vers des objets de type blob, et à y regarder de plus près, ces objets ne sont nuls autres que les 3 blob générés lors de l’ajout de nos fichiers dans l’index.
Ainsi nous avons pu voir que :
- Lorsque l’on ajoute des fichiers à l’index, git crée déjà des objets dans sa base de données et leur attribue des hash. Ces objets ne contiennent que le contenu des fichiers et rien d’autre.
- Lorsque l’on commit, git crée un objet de type commit, qui va se lier à un objet de type tree correspondant à la racine de notre projet, qui lui-même va se lier de façon transitive à nos blobs en passant par des objets de type tree. Les objets de type tree contiennent les informations concernant l’arborescence (nom des fichiers et des dossiers).
Pour afficher l’ensemble des tree, sub-tree et blobs associés au tree-root de master, il suffit donc de taper la commande suivante :
$ git ls-tree -rt master^{tree} --abbrev=7
040000 tree 3ac4d6c conf
100644 blob 244ecfc conf/fileA.txt
040000 tree 8af0164 src
100644 blob 8583cd2 src/fileB.txt
100644 blob 28a3d34 src/fileC.txt
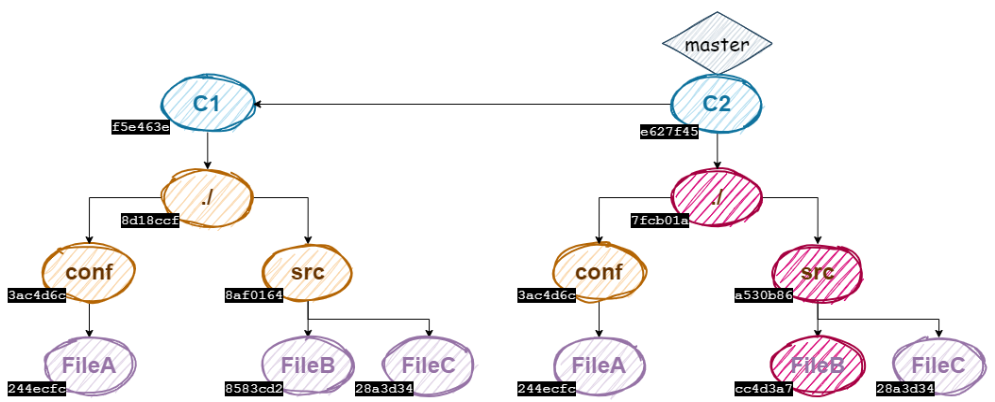
A l’issue de ce premier commit, voici à quoi ressemble notre grappe d’objets git :
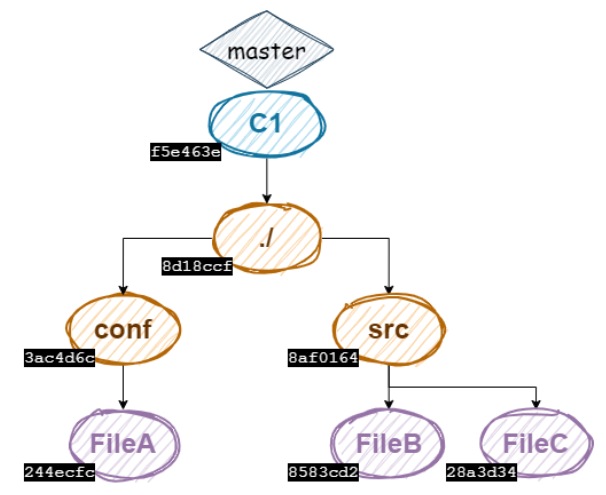
Les plus attentifs d’entre vous auront remarqué que j’ai lié la branche master au commit C1 sur l’illustration ci-dessus alors que nous n’avons pas du tout parlé de branches ! Nous ne développerons pas en profondeur le concept de branches dans cet article puisque ce n’est pas le sujet, mais sachez que les branches sont ni plus ni moins que des références à des commits. Et même si dans notre imaginaire, on peut associer une branche à un ensemble de commits, la réalité est seulement que depuis une branche, nous pouvons accéder à tous les commits ascendants du commit associé à cette branche. Pour vous en convaincre, je vous invite à regarder le contenu du fichier HEAD :
$ cat .git/HEAD
ref: refs/heads/master
Ce fichier contient une référence vers un autre fichier (une autre référence) car nous sommes actuellement attachés à la branche master. Si nous n’étions attachés à aucune branche (état DETACHED), comme par exemple après avoir fait un checkout sur un numéro de commit, alors nous aurions dans ce fichier le numéro de commit en question. Si nous regardons maintenant le contenu du fichier pointé par le HEAD, nous retrouvons bien la référence vers notre commit pointé par master :
$ cat .git/refs/heads/master
f5e463e48ba9dc6b36b072ca3cd03d9c2a0bb70b
Nous avons vu ce qu’il se passait avec un seul commit, mais la réelle force de git réside dans sa façon de versionner les fichiers à travers plusieurs commits et c’est ce qui va nous intéresser à présent.
Les hashes, si simples et pourtant si efficaces !
Maintenant nous allons nous focaliser sur la façon dont git utilise le hash pour ne pas à chaque fois réenregistrer chaque nœud de notre arbre pour les commits qui ne concernent qu’une partie de nos fichiers.
Git va tout simplement se servir du hash pour identifier les nœuds à changer ou à conserver…
Modifions le fichier B avec la commande suivante :
$ echo -n "second content" > src/fileB.txt
On se retrouve avec notre fichier changé dans le working directory, mais rien n’a changé dans l’index :
$ git show :src/fileB.txt
first content B
Nous l’ajoutons donc à l’index :
$ git add src/fileB.txt
$ git status
On branch master
Changes to be committed:
(use "git restore --staged ..." to unstage)
modified: src/fileB.txt
Et on peut facilement constater qu’un nouvel objet cc4d3a7 a été créé :
$ ls .git/objects/ -tR
.git/objects/:
cc/ f5/ 8d/ 8a/ 3a/ 28/ 85/ 24/ info/ pack/
.git/objects/cc:
4d3a7d961604cd89d41a5086f46abb80222775
…Et dans ce fichier nous avons le contenu du fichier qui a été indexé :
$ git cat-file -p cc4d3a7
second content
Pourtant l’ancien objet blob associé au fileB n’a pas bougé et l’arbre associé au commit de master non plus :
$ git ls-tree -rt master^{tree} --abbrev=7
040000 tree 3ac4d6c conf
100644 blob 244ecfc conf/fileA.txt
040000 tree 8af0164 src
100644 blob 8583cd2 src/fileB.txt
100644 blob 28a3d34 src/fileC.txt
Mais si nous procédons au commit :
$ git commit -m "second commit"
[master e627f45] second commit
1 file changed, 1 insertion(+), 1 deletion(-)
Nous avons maintenant un nouvel objet de type commit avec un commit parent pointant vers le précédent commit et un tree-root qui n’a plus le même hash (précédemment 8d18ccf) :
$ git cat-file -p master
tree 7fcb01a509aaae39537b8dd3977818927fbd2846
parent f5e463e48ba9dc6b36b072ca3cd03d9c2a0bb70b
author MarvinElRhumAdorator <marvingilly@gmail.com> 1685633244 +0200
committer MarvinElRhumAdorator <marvingilly@gmail.com> 1685633244 +0200
Maintenant, si nous regardons l’état de notre arbre à partir du tree-root, on peut voir qu’il y a un nouveau blob pour le fichier B et un nouvel objet tree pour le dossier src :
$ git ls-tree -rt master^{tree} --abbrev=7
040000 tree 3ac4d6c conf
100644 blob 244ecfc conf/fileA.txt
040000 tree a530b86 src
100644 blob cc4d3a7 src/fileB.txt
100644 blob 28a3d34 src/fileC.txt
$ git log
* e627f45 (HEAD -> master) second commit
* f5e463e first commit
Ainsi notre graphe d’objets ressemble maintenant à ceci :
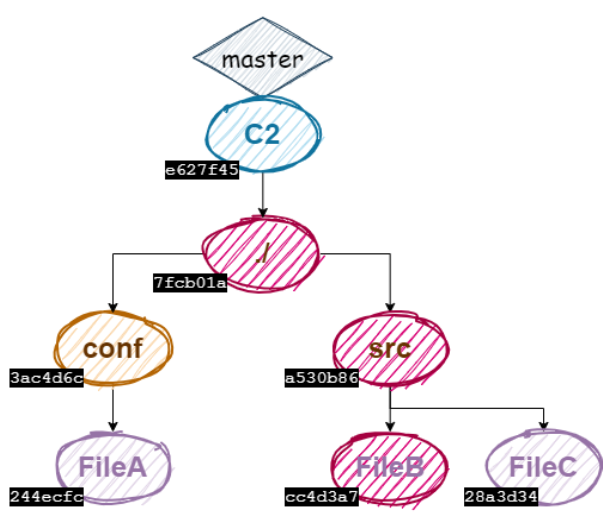
Et nous pouvons en déduire que lorsqu’on commit un nouveau fichier, il y a un nouveau blob pour ce fichier, ainsi que de nouveaux objets de type tree créés entre le nœud blob de ce fichier et le nœud du nouveau commit. L’avantage de ce système est qu’il ne recrée pas une nouvelle version de toute l’arborescence à chaque fois que l’on commit, mais seulement une nouvelle version des nœuds impactés.
En visualisant le schéma de nos 2 arbres de commit avec les hashes de chaque nœud…
On constate que d’un point de vue mémoire, il correspond davantage à celui-ci :
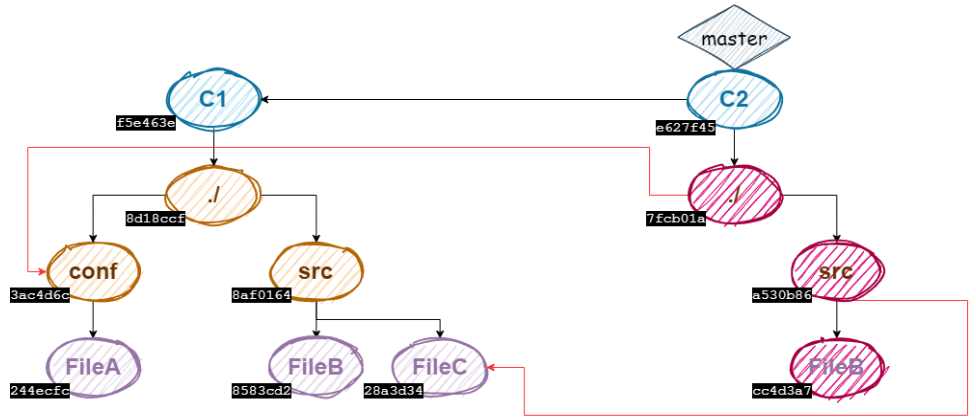
Voici la première couche d’optimisation mémoire que nous avons sur notre versioning git. Parlons maintenant de la deuxième.
La 2è couche d’optimisation de git sur nos commits
Ok, je dois vous faire une confession… J’ai peut-être légèrement menti par souci de simplification en début d’article lorsque j’ai avancé que git ne stockait pas de deltas.
Avec le système de hash, nous ne recréons pas toute l’arborescence à chaque commit, mais avec les explications que nous avons jusque-là, nous comprenons qu’à chaque modification d’un fichier, git crée une toute nouvelle version de ce fichier. Dans la terminologie git, nous parlons de ce type d’objet en tant que loose object.
Pour des fichiers de petite taille, cette recréation n’est pas vraiment un problème. Par contre imaginez un cas, dans lequel on créerait un objet assez volumineux et sur lequel nous effectuerions beaucoup de petites modifications que l’on enregistrerait dans des commits. En fait n’imaginez pas, essayez par vous-même !
Pour ce test, nous avons généré un fichier bigFile.txt dans lequel avec une quantité importante de code généré (avec https://fr.lipsum.com/).
$ ls -1sS src
total 66
64 bigFile.txt
1 fileC.txt
1 fileB.txt
Commitons notre fichier de 64Ko puis procédons à notre expérience :
$ git add src/bigFile.txt
$ git commit -m "create big file"
[master 79ae8c2] create big file
committer MarvinElRhumAdorator <marvingilly@gmail.com> 1685611832
1 file changed, 199 insertions(+)
create mode 100644 src/bigFile.txt
$ git cat-file -p master
tree f38fdd779adbe2da2a04e245fad09c72ff37283d
parent e627f4576d551679ad1d28386150026b12c8e364
author mgilly <marvin.gilly@cpexterne.org> 1701632034 +0100
committer mgilly <marvin.gilly@cpexterne.org> 1701632034 +0100
create big file
$ git ls-tree -rt master^{tree} --abbrev=7
040000 tree 3ac4d6c conf
100644 blob 244ecfc conf/fileA.txt
040000 tree 8b854f7 src
100644 blob afe2ff7 src/bigFile.txt
100644 blob cc4d3a7 src/fileB.txt
100644 blob 28a3d34 src/fileC.txt
$ git cat-file -t afe2ff7
blob
$ git cat-file -s afe2ff7
63093
Comme prévu, nous avons bien notre fichier de presque 64Ko.
Pourtant, lorsqu’on regarde dans le dossier .git/objects/af/ on ne peut voir qu’un fichier de 20 Ko…
$ ls -s .git/objects/af/
total 20
20 e2ff73b88635f1ea6d2468d82b3cc6470dd85b
Eh bien cela s’explique tout simplement par le fait que git utilise une librairie de compression (https://www.zlib.net/) pour stocker tous nos objets. Mais ce n’est pas l’optimisation que nous cherchons à révéler ici.
Je vous propose pour notre expérience de faire 2 commits consistant à ajouter des petites modifications à la fin de notre fichier volumineux.
$ echo "une meilleure fin" >> src/bigFile.txt
$ git add src/bigFile.txt
$ git commit -m "la meilleure fin"
[master d5aa1eb] la meilleure fin
Committer: mgilly <marvin.gilly@cpexterne.org>
1 file changed, 1 insertion(+), 1 deletion(-)
$ git ls-tree -rt master^{tree} --abbrev=7
040000 tree 3ac4d6c conf
100644 blob 244ecfc conf/fileA.txt
040000 tree 6f1bb7d src << nouveau tree
100644 blob d0bb954 src/bigFile.txt << nouveau fichier
100644 blob cc4d3a7 src/fileB.txt
100644 blob 28a3d34 src/fileC.txt
$ echo " qui n'était pas vraiment une fin" >> src/bigFile.txt
$ git commit -am "une autre fin"
[master 2493172] une autre fin
Committer: mgilly <marvin.gilly@cpexterne.org>
1 file changed, 1 insertion(+)
$ git ls-tree -rt master^{tree} --abbrev=7
040000 tree 3ac4d6c conf
100644 blob 244ecfc conf/fileA.txt
040000 tree b634e49 src << nouveau tree
100644 blob c5c46ea src/bigFile.txt << nouveau fichier
100644 blob cc4d3a7 src/fileB.txt
100644 blob 28a3d34 src/fileC.txt
L’expérience nous montre que git nous a créé 2 nouveaux blobs du fichiers (d0bb954 et c5c46ea) ainsi que les tree associés.
On vérifie que les 3 fichiers correspondants à afe2ff73, d0bb954 et c5c46ea existent toujours avec environ la même taille :
$ find .git/objects/ -type f | grep '/d0\|/af\|/c5' | xargs ls -s
20 .git/objects/af/e2ff73b88635f1ea6d2468d82b3cc6470dd85b
20 .git/objects/c5/c46ea43f623538f1c9255660f5b367d01617ce
20 .git/objects/d0/bb954504fbfbcdec2a2e0841a6d121a109d621
Voilà c’est drôlement dommage, il semblerait que git ne soit pas optimisé et que nous puissions lancer un nouvel outil de versionning en open source… Ou pas !
En fait il ne s’est rien passé car l’optimisation que nous souhaitons voir se produire repose sur la commande git gc. Cette commande nettoie et optimise le repo local mais n’est déclenchée que lorsque git détecte que le “dépôt a grandi de façon substantielle” depuis son dernier déclenchement. Personnellement je n’ai pas envie de voir au bout de combien de commits git estimera que le repo a assez grandi pour déclencher notre nettoyage de printemps, alors je vous propose que nous le déclenchions manuellement !
Affichons d’abord tous les objets présents avant le déclenchement de notre commande :
$ git rev-list --all --objects
2493172
d5aa1eb
79ae8c2
e627f45
f5e463e
9216001
3ac4d6c conf
244ecfc conf/fileA.txt
b634e49 src
c5c46ea src/bigFile.txt
cc4d3a7 src/fileB.txt
28a3d34 src/fileC.txt
d3d78ef
6f1bb7d src
d0bb954 src/bigFile.txt
f38fdd7
8b854f7 src
afe2ff7 src/bigFile.txt
7fcb01a
a530b86 src
8d18ccf
8af0164 src
8583cd2 src/fileB.txt
Et maintenant déclenchons notre gc :
$ git gc
Enumerating objects: 23, done.
Counting objects: 100% (23/23), done.
Delta compression using up to 12 threads
Compressing objects: 100% (18/18), done.
Writing objects: 100% (23/23), done.
Total 23 (delta 2), reused 0 (delta 0), pack-reused 0
Plusieurs choses intéressantes sont à relever ici :
- Il y a 23 objets traités dans le gc
- 18 sont compressés
- 2 sont construits par delta
Étant donné que l’on a 5 commits, il est facile de comprendre qu’on a compressé 23 – 5 objets.
Vérifions si nos anciens blobs existent encore :
$ find .git/objects/ -type f | grep '/d0\|/af\|/c5'
Les fichiers n’existent plus… Pourtant quand on regarde à quoi sont rattachés nos 2 derniers commits, nous avons toujours les mêmes références vers c5c46ea et d0bb954 :
$ git ls-tree -rt master^{tree} --abbrev=7
040000 tree 3ac4d6c conf
100644 blob 244ecfc conf/fileA.txt
040000 tree b634e49 src
100644 blob c5c46ea src/bigFile.txt
100644 blob cc4d3a7 src/fileB.txt
100644 blob 28a3d34 src/fileC.txt
$ git ls-tree -rt master^^{tree} --abbrev=7
040000 tree 3ac4d6c conf
100644 blob 244ecfc conf/fileA.txt
040000 tree 6f1bb7d src
100644 blob d0bb954 src/bigFile.txt
100644 blob cc4d3a7 src/fileB.txt
100644 blob 28a3d34 src/fileC.txt
Les seules choses que nous avons dans le dossiers .git/objects sont des infos concernant notre nouveau packfile :
$ find .git/objects/ -type f
.git/objects/info/commit-graph
.git/objects/info/packs
.git/objects/pack/pack-b437ade7134f34da0d842375918dcc1fce88154d.idx
.git/objects/pack/pack-b437ade7134f34da0d842375918dcc1fce88154d.pack
.git/objects/pack/pack-b437ade7134f34da0d842375918dcc1fce88154d.rev
La commande gc que nous avons faite a rassemblé les nœuds rattachés à des commits dans notre packfile (et simplement supprimé les noeuds rattachés à aucun commit).
Nous pouvons visualiser le contenu de notre packfile pour essayer de comprendre où sont passés nos différents noeuds :
$ git verify-pack -v .git/objects/pack/pack-b437ade7134f34da0d842375918dcc1fce88154d.idx -v
2493172 commit 232 155 12
d5aa1eb commit 235 158 167
79ae8c2 commit 234 155 325
e627f45 commit 248 165 480
f5e463e commit 199 133 645
244ecfc blob 15 24 778
c5c46ea blob 63146 17562 802
cc4d3a7 blob 14 21 18364
28a3d34 blob 15 24 18385
9216001 tree 61 69 18409
3ac4d6c tree 37 48 18478
b634e49 tree 113 106 18526
d3d78ef tree 61 68 18632
6f1bb7d tree 113 106 18700
d0bb954 blob 9 21 18806 1 c5c46ea
f38fdd7 tree 61 68 18827
8b854f7 tree 113 106 18895
afe2ff7 blob 9 21 19001 1 c5c46ea
7fcb01a tree 61 68 19022
a530b86 tree 74 75 19090
8d18ccf tree 61 69 19165
8af0164 tree 74 75 19234
8583cd2 blob 15 24 19309
non delta: 21 objects
chain length = 1: 2 objects
.git/objects/pack/pack-b437ade7134f34da0d842375918dcc1fce88154d.pack: ok
On peut voir qu’il y a 21 noeuds qui ont été repris dans le packfile tels qu’ils étaient avant et 2 nœuds qui ont été construits par delta. En filtrant et abrégeant les hashes on obtient bien le hash de notre première version de bigFile.txt avec une taille de 63Ko ainsi que les 2 autres versions du bigFile qui font respectivement 9 octets chacun. Ici nul doute que l’optimisation est au rendez-vous !
Le petit mot de la fin
Bravo à toi cher lecteur, tu as su braver toutes ces commandes git bas niveau et maintenant le système de commits n’a plus de secrets pour toi ! Pour autant, dans ta vie de tous les jours tu seras sans doute plus souvent amené à utiliser des commandes de porcelaine (haut niveau) que des commandes de plomberie (cat-file, rev-list, …). C’est pourquoi, je t’invite à découvrir les bases de git avec ce tuto git, avant peut-être de creuser sur des pratiques plus avancées comme le reflog, le bissect, et tant d’autres.
A bientôt pour un prochain article qui nous ramènera sur un thème plus craft.
Bonus
Sur les terminaux linux, vous pouvez à travers la librairie openssl, utiliser zlib sur les fichiers de votre répertoire .git/objects/ pour en visualiser le contenu, comme ici :
openssl zlib -d -in .git/objects/45/6090b9ef17b58856f25b59e96bcae03914590a
*pour simplifier nous omettons les optimisations faites dans les packs
Marvin Gilly – El Rhum Adorator