
Dans le premier article, nous avons vu que la qualité des logs dans une application est essentielle, comment les revoir régulièrement et les centraliser pour un diagnostic efficace en cas de problème. Cependant, le logging étant une fonction essentielle, mais aussi transversale et secondaire, on peut se demander où doit se situer la responsabilité de sa gestion ?
Le fait que la fonctionnalité soit secondaire peut amener à décider que chaque service puisse gérer ses logs comme bon lui semble, que ce soit leur forme ou leur destination, en respectant le principe d’indépendance des services. Cependant, le logging est aussi une fonctionnalité transversale à toute l’application, et son caractère essentiel impose une certaine cohérence entre les services. Dès lors, on peut imaginer découpler les microservices de la gestion des logs, en déléguant cette responsabilité à un service centralisé.
Pour y arriver, nous allons voir deux pistes qui peuvent être complémentaires :
- Un microservice hébergeant la configuration des services, en particulier du logging ;
- Un autre microservice dédié à la télémétrie, qui irait chercher les logs de chacun des services et les enverrait à leur destination finale, après les avoir filtrés voire pré-agrégés.
La configuration des microservices
Pour des raisons de maintenabilité et de gestion de multiples environnements (DEV, QA, PREPROD, PROD, etc), les services ont d’ordinaire un fichier de configuration auquel ils se réfèrent pour configurer certains services tiers. Cela peut être une base de données, une API externe, ou dans le cas qui nous intéresse, les informations de configuration des logs.
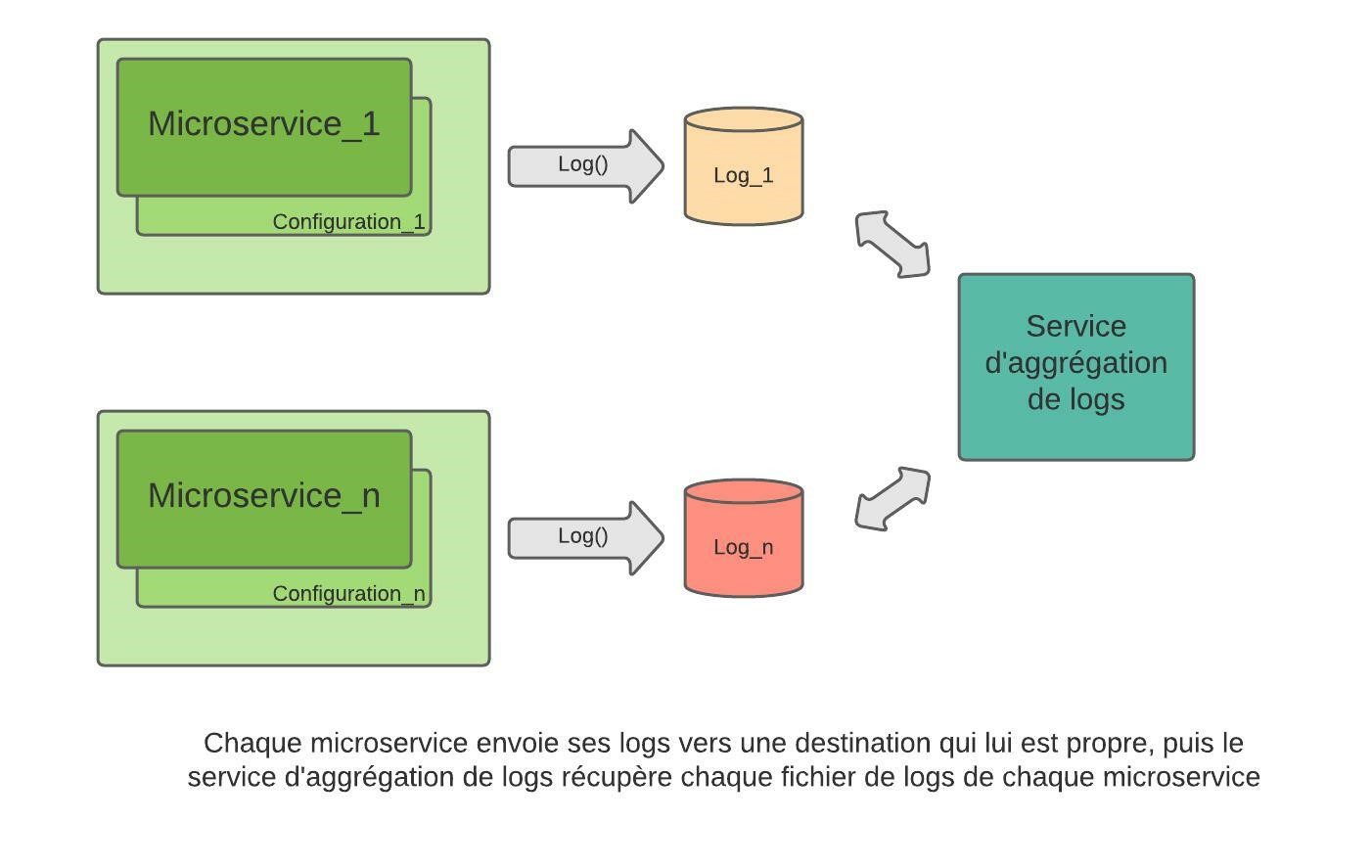
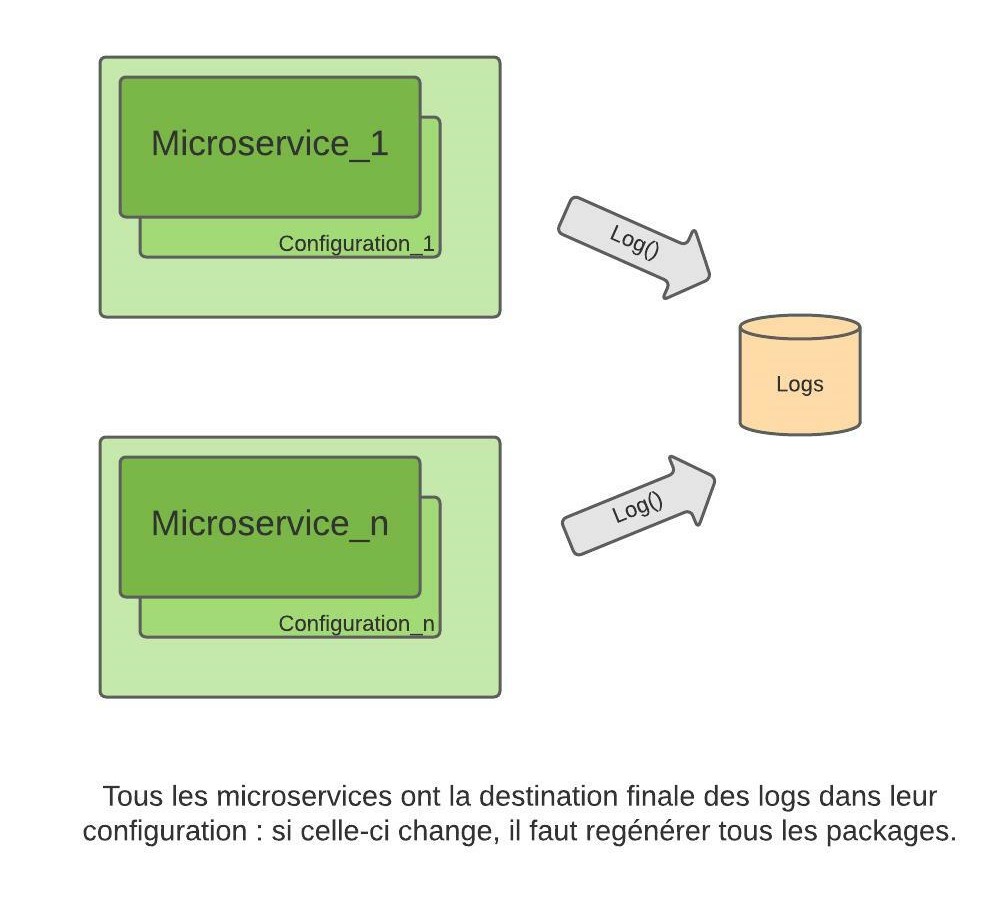
Dans un contexte microservices, chaque service a son fichier de configuration propre. En ce qui concerne les fonctionnalités très transversales comme les logs, deux approches sont possibles : soit on décide que chaque service gère ses propres logs à sa façon, en suivant un principe d’indépendance des services ; soit les mêmes informations de configuration sont dupliquées entre les services.
Dans le premier cas, on retrouve le problème que nous avons abordé dans le premier article : l’interprétation des logs se révèle délicate sans un bon système d’agrégation. Dans le deuxième cas, les informations dupliquées rendent toute modification de configuration fastidieuse : chaque fichier de configuration de chaque service devra être mis à jour, et dans la majorité des cas, le service devra être redémarré voire redéployé.
External Configuration Store pattern
Ce pattern consiste en l’externalisation de la configuration des microservices dans un autre service dédié, auquel ils font référence lors de leur démarrage et/ou périodiquement, pour récupérer les informations qui les concernent. La seule configuration nécessaire au niveau du microservice est le moyen d’accès au service de configuration, et cela est indépendant de l’environnement sur lequel le microservice est déployé.
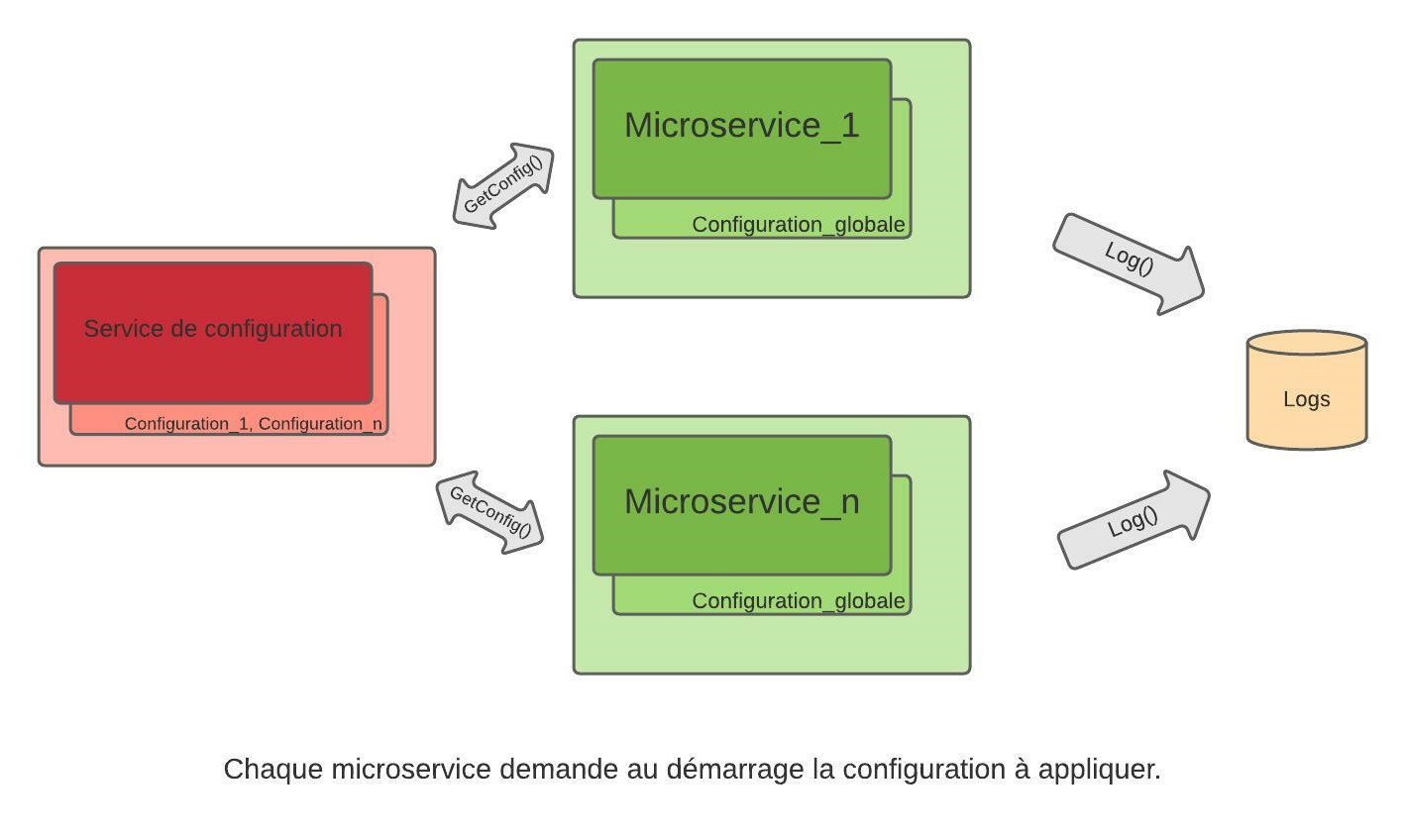
Pour stocker les informations de configuration, on peut imaginer n’importe quelle solution ; du système de fichier au cloud, en passant par la base de données ou un service stateful (c’est-à-dire qu’il garde un statut en mémoire avec les informations de configuration, même en cas de redémarrage). L’important est son rôle : il est dédié au stockage et à la restitution des informations de configuration à la demande.
Certains critères doivent être respectés :
- Le stockage des données sera idéalement structuré : plusieurs valeurs doivent pouvoir être entrées pour correspondre à chaque environnement. Une valeur par défaut doit être prévue.
- Le service doit comporter une interface de requête simple d’accès : par exemple, il peut s’agir d’une API REST.
- Les appels devront être authentifiés pour protéger les données.
- Le service doit évidemment être léger, suffisamment efficace en termes de performance, et robuste. Pas de processus lourd et risqué qui pourrait le faire crasher, et empêcher les autres services de démarrer convenablement.
Un livrable unique par microservice
Grâce à cette solution, un seul package par service est nécessaire pour chacun des environnements utilisés, ce qui simplifie la release et préserve de certaines erreurs : le même package peut être testé sur une plateforme, puis déployé en production. Pas de modification de fichier entre les plateformes, encore moins de recompilation. S’il y a un problème, c’est forcément un souci de configuration !
On retrouve ce même système sur certains outils de déploiement comme Octopus Deploy : on a un seul livrable par microservice dans la librairie de packages, et on a défini des variables de configuration avec une valeur par environnement. Le remplacement des valeurs de configuration se fait au déploiement de chaque microservice.
Avec le service de configuration, en plus de récupérer les informations qui les concernent quand ils démarrent, les microservices peuvent aussi demander périodiquement des mises à jour de configuration pendant leur cycle de vie. Par exemple, dans le cas des logs, on peut imaginer que lors d’un souci en production, on ait envie de modifier le niveau de logs pour avoir plus de détails sur ce qui se passe. C’est possible avec cette approche : on modifie alors la configuration des logs au niveau du service de configuration, et les autres microservices prendront en compte la nouvelle information lors d’une mise à jour périodique, et produiront plus de logs !
Single point of failure
L’idée est bonne sur le papier, mais nous sommes confrontés à un problème de taille : que se passe-t-il si le service de configuration crashe ? Il se révèle être un single point of failure pour toute l’application : s’il ne répond pas, personne ne peut démarrer. Une configuration par défaut se révèle alors indispensable.
C’est d’autant plus gênant dans le cas des logs : fonctionnalité transversale, essentielle, mais tout de même secondaire. En aucun cas un service ne doit crasher s’il ne peut pas loguer ! Un problème de logging ne doit pas être bloquant pour le service, qui doit continuer à jouer son rôle.
Alors comment découpler convenablement la gestion des logs et les microservices ?
Une manière de loguer légère
Pour commencer, rendons le microservice agnostique vis à vis de la librairie de logs. L’idée est de diriger les logs vers une destination tellement simple et évidente de son point de vue, que d’une part ça ne pourra pas le faire crasher, mais en plus cela ne lui coûtera pas grand-chose en termes de performance. Ce sera d’autant plus simple d’exploiter les logs ensuite, puisque leur destination est standard.
La légèreté de ces solutions permet de s’affranchir pour l’instant du filtrage ou de l’optimisation des logs ; on peut se permettre de tout envoyer, du simple log debug ou informatif, au log critique. L’étape suivante se chargera elle-même de faire le tri.
Utilisation des sorties standards
Si on est sous Windows, une première solution serait d’utiliser ETW (Event Tracing for Windows). C’est un système de diagnostic intimement lié au système d’exploitation, supporté de longue date sur le Framework .Net, et de mieux en mieux au fil des versions. D’autre part, les librairies de logs, dont nous avons parlé dans le premier article, ont développé les sink / target associés pour envoyer les logs vers cette destination (voici par exemple un package pour Serilog et la documentation pour NLog).
Les logs émis sont enregistrés dans le journal des événements windows, et visualisables dans le journal des événements Windows, en direct via des applications comme PerfView, et récupérables par les applications de manière in-process (c’est-à-dire dans le code même de l’application qui a produit le log) ou out-of-process (via un processus tiers) via des listeners.
Une autre solution plus simple encore pour le microservice, quelle que soit la plateforme, est d’utiliser les flux de sortie standard (stdout) et erreur (stderr) des applications. C’est souvent le mode par défaut lorsqu’on crée une application, cela demande donc encore moins de configuration.
De nombreux outils comme Kubernetes, Filebeat (agent installé sur les machines qui collecte des évènements, fichiers de logs, etc), et bien d’autres, permettent d’accéder à ces flux et de traiter les informations récupérées. Un microservice dédié à cela peut aussi être créé dans notre application, ou bien prendre la forme d’un service externe qui collecterait tous les logs d’une machine.
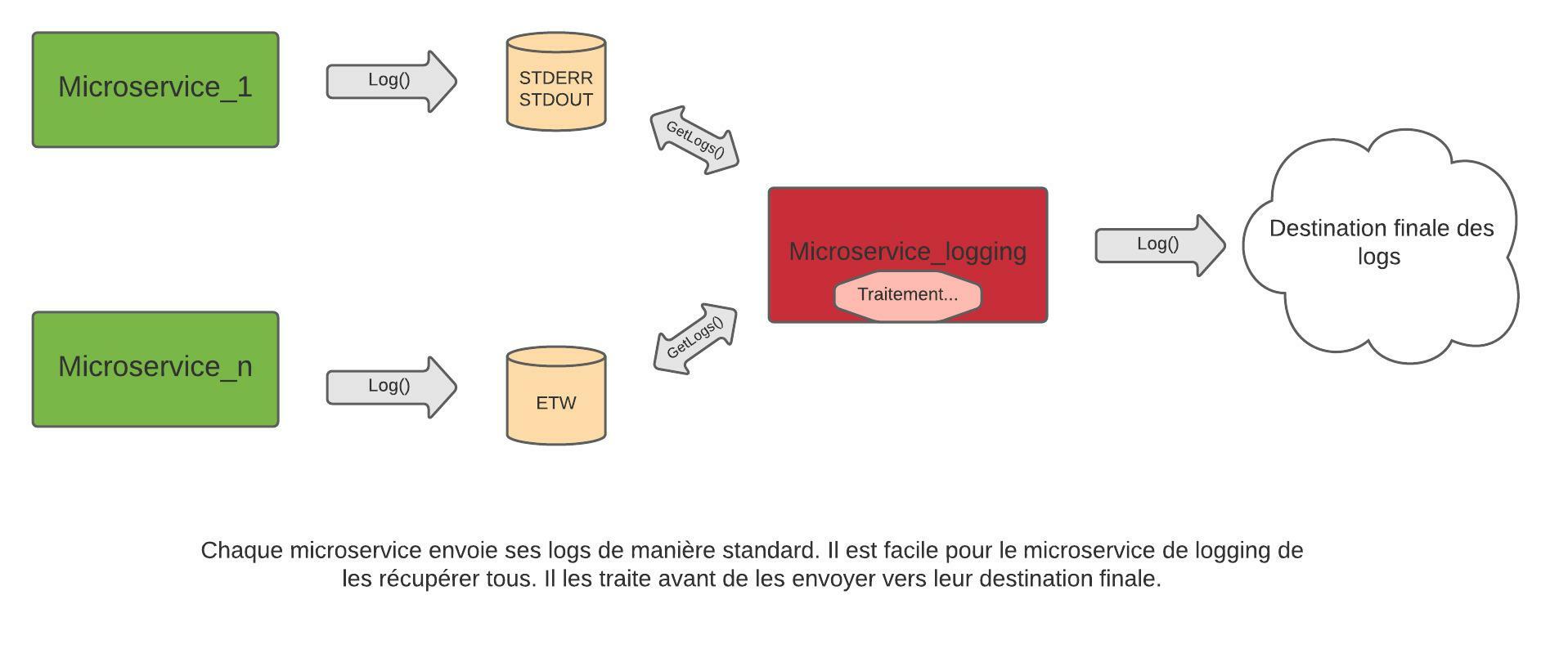
Un microservice dédié à la télémétrie
On est donc parfaitement capables de récupérer ces logs standards à postériori, par exemple avec des outils existants ou avec un microservice dédié. Il sera déployé sur toutes les machines où se trouvent des microservices de l’application, et ira chercher tous les logs sur les destinations standards. Il pourra ensuite les filtrer (niveau de log, catégorie, …), voire les pré-agréger entre logs similaires ou en y ajoutant diverses informations, avant de les envoyer vers leur destination finale, dont lui seul aura connaissance.
Il pourra aussi profiter de sa position pour enrichir les logs d’autres informations de télémétrie sur les processus des services, des compteurs de performance, des informations de santé sur la machine… pour avoir une vision plus globale de la santé de l’application et aider au diagnostic.
Et c’est ensuite lui qui se chargera d’envoyer toutes ces informations vers leur destination finale, un service de centralisation de logs par exemple, comme nous l’avons évoqué dans le premier article.
Conclusion
L’un des principes fondateurs des applications microservices est la séparation des responsabilités. Chaque microservice est responsable d’une unique fonction. Nous avons vu dans cet article l’intérêt d’avoir des microservices agnostiques des fonctions transversales telles que le logging. Pour cela, une externalisation de la configuration est envisageable, ce qui permet d’obtenir des packages uniques à déployer sur toutes les plateformes, et rend même possible une reconfiguration durant la vie des microservices.
Cependant nous avons aussi pointé le fait que, du point de vue des microservices, il est préférable que la création de logs soit aussi générique que possible pour en permettre une gestion centralisée dans le cluster. La responsabilité des logs n’incombe alors plus à nos microservices, et elle peut être déléguée à un service spécifique, présent sur le marché, ou bien développé par l’équipe selon les besoins de l’application. Il aura pour rôle de récupérer, filtrer, agréger, et envoyer les logs et données de télémétrie à leur destination finale, où les informations pourront être traitées. Sa configuration à lui aussi peut évidemment être externalisée, offrant une grande souplesse dans la gestion des logs.
Carole CHEVALIER